
Problem Overview
Deep learning has become a crucial component of many companies’ data analysis pipelines. To further enhance the performance of deep learning models, researchers have developed various optimization algorithms. An optimizer improves the model by adjusting its parameters (weights and biases) to minimize the loss function value. Having multiple optimizers available means that different algorithms can be used to adjust the parameters to minimize the loss function value. Hence, this study provides an experiment with five optimizers to assess their performance on a neural network classifier. The following Optimizers will be used:
- Stochastic Gradient Descent (SGD)
- Adam
- RMSprop
- Adagrad
- Nadam
Dataset
In view of this, this study aims to compare how each of these optimizer perform using the MNISt dataset. I load the dataset using the below code:
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
The dimension of the training dataset is (60000, 28, 28). In this case, I have set aside 10000 images and their corresponding as a validation set. The remaining set will be labelled as the training set.
Exploratortion
A quick view of the data using the code below yields the picture below:

Before I feed the images into the neural network, I normalize the pixel values by dividing them by 255. This scales all pixel values from the original range of 0–255 down to a range of 0–1. This step helps my model train faster and more effectively by keeping the input values small and consistent, which improves the stability of the learning process.
def preprocess_images(images):
return images.reshape((-1, 28, 28, 1)) / 255.0
train_images = preprocess_images(train_images)
validation_images = preprocess_images(validation_images)
X_test = preprocess_images(X_test)

The code below shows the list of the different optimizers used for this analysis.
optimizers = {
'Adam': Adam(learning_rate=0.001),
'SGD': SGD(learning_rate=0.001),
'RMSprop': RMSprop(learning_rate=0.001),
'Adagrad': Adagrad(learning_rate=0.001)}
The model architecture using for this study is shown below:
def create_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
return model
The results that follow shows the output from the experiment.
Optimizer Comparison: The final line compares the performance of four optimizers:
- Adam: Achieved an accuracy of 0.8476
- SGD (Stochastic Gradient Descent): Achieved an accuracy of 0.1411
- RMSprop: Achieved an accuracy of 0.1000
- Adagrad: Achieved an accuracy of 0.1000
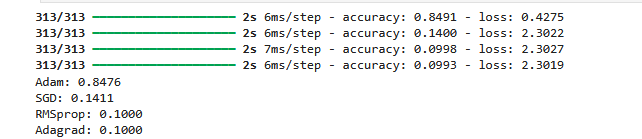
Based on the output, Adam seems to be the best-performing optimizer for your model, with an accuracy of 0.8476. The other optimizers (SGD, RMSprop, and Adagrad) resulted in significantly lower accuracy values. Hence the Adam will be chosen for hyperparameter tuning.
## The results suggest that:
- The model performs well with a learning rate of 0.001, achieving an accuracy of 0.8254.
- The model struggles with higher learning rates (0.01 and 0.1), resulting in very poor accuracy.