
Problem Overview
Customer reviews are a crucial source of feedback for businesses, but traditional models often struggle to accurately capture the nuances of text-based reviews. In an attempt to address this, this study focuses on sentiment classification of movie reviews using advanced Transformer-based language models and representation learning techniques. The goal is to evaluate and compare the performance of two modern NLP approaches — direct classification using a fine-tuned Transformer and feature-based classification using sentence embeddings. The purpose of utilizing pre-trained models, is to bridge the gap between customer sentiment and business understanding, enabling more informed decision-making and improved customer satisfaction.
Reseach quesion
In view of this, the following research questions will guide this study:
- How accurately can pre-trained language models classify sentiment in customer reviews?
- Which pre-trained model (e.g., BERT, RoBERTa, XLNet) performs best for sentiment analysis of customer reviews?
Dataset
The dataset used is this study is the Rotten Tomatoes dataset, which contains movie reviews labeled as positive or negative. The dataset was loaded using the Hugging Face datasets library and it has been splitted into training and test subsets.
from datasets import load_dataset
data = load_dataset("rotten_tomatoes")
Methodology
Two models are compare here: a. Transformer-based Sentiment Classification (RoBERTa Model): This is the first approach is usinfg the RoBERTa-base model, specifically the version fine-tuned on tweets for sentiment analysis (cardiffnlp/twitter-roberta-base-sentiment-latest).
The model was loaded using the Hugging Face pipeline API.
# Path to our model
model_path = "cardiffnlp/twitter-roberta-base-sentiment-latest"
# Load model into pipeline
pipe = pipeline(model=model_path, tokenizer=model_path, return_all_scores=True)
I performed inference on the test data to obtain sentiment predictions.
Below indicate the results for the inference.
| Class | Precision | Recall | F1-score | Support |
|---|---|---|---|---|
| Negative Review | 0.76 | 0.88 | 0.81 | 533 |
| Positive Review | 0.86 | 0.72 | 0.78 | 533 |
| Accuracy | 0.80 | 1066 | ||
| Macro Avg | 0.81 | 0.80 | 0.80 | 1066 |
| Weighted Avg | 0.81 | 0.80 | 0.80 | 1066 |
From the results above, the model achieved an accuracy of 80% with 1066 instances, showing balanced performance across both negative and positive reviews with macro and weighted averages of 0.80, while precision, recall, and F1-score varied between classes, with 0.76 precision for negative reviews and 0.86 precision for positive reviews.
I move on to explore the performance of the second methods.
b. Sentence Embedding + Logistic Regression Model This approach uses the Sentence-Transformers framework (all-mpnet-base-v2) to convert each text into a 768-dimensional embedding vector. Then the embeddings are used as features to train a Logistic Regression classifier for binary sentiment prediction.
# Load model
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
# Convert text to embeddings
train_embeddings = model.encode(data["train"]["text"], show_progress_bar=True)
test_embeddings = model.encode(data["test"]["text"], show_progress_bar=True)
# Train a logistic regression on our train embeddings
clf = LogisticRegression(random_state=42)
clf.fit(train_embeddings, data["train"]["label"])
The trained model was tested on unseen data, and performance was evaluated similarly using classification metrics.
| Class | Precision | Recall | F1-score | Support |
|---|---|---|---|---|
| Negative Review | 0.85 | 0.86 | 0.85 | 533 |
| Positive Review | 0.86 | 0.85 | 0.85 | 533 |
| Accuracy | 0.85 | 1066 | ||
| Macro Avg | 0.85 | 0.85 | 0.85 | 1066 |
| Weighted Avg | 0.85 | 0.85 | 0.85 | 1066 |
From the output above, the model achieved an accuracy of 85% with 1066 instances, demonstrating consistent performance across both negative and positive reviews with identical macro and weighted averages of 0.85 for precision, recall, and F1-score.
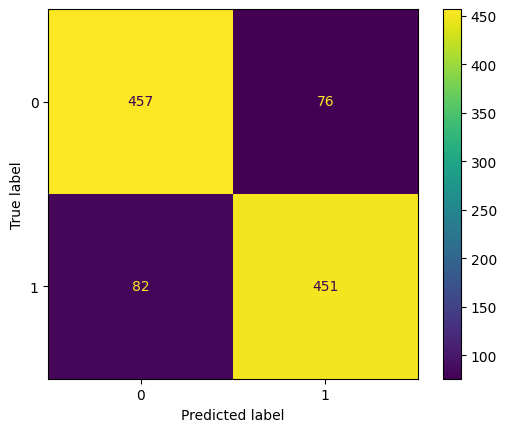
The output above indicate that the model correctly classifies most examples of both classes (0 and 1), with about 15% of predictions incorrect. It shows good overall precision and recall, indicating a strong and balanced binary classifier.
Evaluation and Analysis
The RoBERTa sentiment classifier provided direct predictions from the pretrained model, offering insight into transformer-based text classification performance.
The embedding-based logistic regression model demonstrated how learned sentence representations can serve as effective features for traditional machine learning classifiers.
A confusion matrix was plotted to visualize prediction results and identify areas where the model struggled.
Misclassified examples were examined to analyze model errors and potential areas for improvement.
Number of misclassified examples: 158
-
Text: it’s like a “ big chill “ reunion of the baader-meinhof gang , only these guys are more harmless pranksters than political activists . True: 1, Predicted: 0
-
Text: mostly , [goldbacher] just lets her complicated characters be unruly , confusing and , through it all , human . True: 1, Predicted: 0
-
Text: at its worst , the movie is pretty diverting ; the pity is that it rarely achieves its best . True: 1, Predicted:
The output shows examples of text classification errors, where a model incorrectly predicted the sentiment of movie reviews as negative (0) when the actual sentiment was positive (1).
Conclusion
This study demonstrated how Transformer-based models can be leveraged for sentiment analysis either directly (via fine-tuned classification pipelines) or indirectly (via learned embeddings for downstream models). Such approaches highlight the versatility and power of modern NLP techniques for text understanding tasks, providing a foundation for further work in transfer learning and model interpretability in sentiment analysis.